Note
This page was generated from
Kang.ipynb.
Interactive online version:
![]() .
.
Predicting perturbation responses for unseen cell-types (context transfer)#
In this tutorial, we will train and evaluate a CPA model on the preprocessed Kang PBMC dataset (See Sup Figures 2-3 here for a deeper dive).
The following steps are going to be covered: 1. Setting up environment 2. Loading the dataset 3. Preprocessing the dataset 4. Creating a CPA model 5. Training the model 6. Latent space visualisation 7. Prediction evaluation across different perturbations
Setting up environment#
[1]:
import sys
#if branch is stable, will install via pypi, else will install from source
branch = "latest"
IN_COLAB = "google.colab" in sys.modules
if IN_COLAB and branch == "stable":
!pip install cpa-tools
!pip install scanpy
elif IN_COLAB and branch != "stable":
!pip install --quiet --upgrade jsonschema
!pip install git+https://github.com/theislab/cpa
!pip install scanpy
[2]:
import os
# os.chdir('/home/mohsen/projects/cpa/')
# os.environ['CUDA_VISIBLE_DEVICES'] = '0'
[3]:
import cpa
import scanpy as sc
Global seed set to 0
[4]:
sc.settings.set_figure_params(dpi=100)
[5]:
data_path = '/home/mohsen/projects/cpa/datasets/kang_normalized_hvg.h5ad'
Loading dataset#
The preprocessed Kang PBMC dataset with h5ad extension used for saving/loading anndata objects is publicly available in the Google Drive and can be loaded using the sc.read function with the backup_url argument. The datasets is normalized & pre-processed using scanpy. Top 5000 highly variable genes are selected.
[6]:
try:
adata = sc.read(data_path)
except:
import gdown
gdown.download('https://drive.google.com/uc?export=download&id=1z8gGKQ6oDoi2blCU2IVihKA38h5fORRp')
data_path = 'kang_normalized_hvg.h5ad'
adata = sc.read(data_path)
adata
[6]:
AnnData object with n_obs × n_vars = 13576 × 5000
obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'stim', 'seurat_annotations', 'integrated_snn_res.0.5', 'seurat_clusters', 'condition', 'cell_type', 'cov_cond', 'split_CD14 Mono', 'split_CD4 T', 'split_T', 'split_CD8 T', 'split_B', 'split_DC', 'split_CD16 Mono', 'split_NK'
var: 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'symbol'
uns: 'hvg', 'log1p', 'rank_genes_groups_cov'
layers: 'counts'
Next, we just replace adata.X with raw counts to be able to train CPA with Negative Binomial (NB) or Zero-Inflated Negative Binomial (ZINB) loss.
[7]:
adata.X = adata.layers['counts'].copy()
Dataset setup#
Now is the time to setup the dataset for CPA to prepare the dataset for training. Just like scvi-tools models, you can call cpa.CPA.setup_anndata to setup your data. This function will accept the following arguments:
adata: AnnData object containing the data to be preprocessedperturbation_key: The key inadata.obsthat contains the perturbation informationcontrol_group: The name of the control group inperturbation_keybatch_key: The key inadata.obsthat contains the batch informationdosage_key: The key inadata.obsthat contains the dosage informationcategorical_covariate_keys: A list of keys inadata.obsthat contain categorical covariatesis_count_data: Whether theadata.Xis count data or notdeg_uns_key: The key inadata.unsthat contains the differential expression resultsdeg_uns_cat_key: The key inadata.obsthat contains the category information of each cell which can be used as to access differential expression results inadata.uns[deg_uns_key]. For example, ifdeg_uns_keyisrank_genes_groups_covanddeg_uns_cat_keyiscov_cond, thenadata.uns[deg_uns_key][cov_cond]will contain the differential expression results for each category incov_cond.max_comb_len: The maximum number of perturbations that are applied to each cell. For example, ifmax_comb_lenis 2, then the model will be trained to predict the effect of single perturbations and the effect of double perturbations.
We will create a dummy dosage variable for each condition (control, IFN-beta stimulated). It is recommended to use Identity (i.e. doser_type = ‘identity’) for dosage scaling function when there is no dosage information available.
[8]:
adata.obs['dose'] = adata.obs['condition'].apply(lambda x: '+'.join(['1.0' for _ in x.split('+')]))
[9]:
adata.obs['cell_type'].value_counts()
[9]:
CD14 Mono 4362
CD4 T 4266
B 1366
CD16 Mono 1044
CD8 T 814
T 633
NK 619
DC 472
Name: cell_type, dtype: int64
[10]:
adata.obs['condition'].value_counts()
[10]:
stimulated 7217
ctrl 6359
Name: condition, dtype: int64
[11]:
cpa.CPA.setup_anndata(adata,
perturbation_key='condition',
control_group='ctrl',
dosage_key='dose',
categorical_covariate_keys=['cell_type'],
is_count_data=True,
deg_uns_key='rank_genes_groups_cov',
deg_uns_cat_key='cov_cond',
max_comb_len=1,
)
100%|██████████| 13576/13576 [00:00<00:00, 85425.58it/s]
100%|██████████| 13576/13576 [00:00<00:00, 1004744.25it/s]
100%|██████████| 16/16 [00:00<00:00, 1797.82it/s]
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
INFO Generating sequential column names
INFO Generating sequential column names
INFO Generating sequential column names
INFO Generating sequential column names
[13]:
model_params = {
"n_latent": 64,
"recon_loss": "nb",
"doser_type": "linear",
"n_hidden_encoder": 128,
"n_layers_encoder": 2,
"n_hidden_decoder": 512,
"n_layers_decoder": 2,
"use_batch_norm_encoder": True,
"use_layer_norm_encoder": False,
"use_batch_norm_decoder": False,
"use_layer_norm_decoder": True,
"dropout_rate_encoder": 0.0,
"dropout_rate_decoder": 0.1,
"variational": False,
"seed": 6977,
}
trainer_params = {
"n_epochs_kl_warmup": None,
"n_epochs_pretrain_ae": 30,
"n_epochs_adv_warmup": 50,
"n_epochs_mixup_warmup": 0,
"mixup_alpha": 0.0,
"adv_steps": None,
"n_hidden_adv": 64,
"n_layers_adv": 3,
"use_batch_norm_adv": True,
"use_layer_norm_adv": False,
"dropout_rate_adv": 0.3,
"reg_adv": 20.0,
"pen_adv": 5.0,
"lr": 0.0003,
"wd": 4e-07,
"adv_lr": 0.0003,
"adv_wd": 4e-07,
"adv_loss": "cce",
"doser_lr": 0.0003,
"doser_wd": 4e-07,
"do_clip_grad": True,
"gradient_clip_value": 1.0,
"step_size_lr": 10,
}
CPA Model#
You can create a CPA model by creating an object from cpa.CPA class. The constructor of this class takes the following arguments: Data related parameters: - adata: AnnData object containing train/valid/test data - split_key: The key in adata.obs that contains the split information - train_split: The value in split_key that corresponds to the training data - valid_split: The value in split_key that corresponds to the validation data - test_split: The value
in split_key that corresponds to the test data Model architecture parameters: - n_latent: Number of latent dimensions - recon_loss: Reconstruction loss function. Currently, Supported losses are nb, zinb, and gauss. - n_hidden_encoder: Number of hidden units in the encoder - n_layers_encoder: Number of layers in the encoder - n_hidden_decoder: Number of hidden units in the decoder - n_layers_decoder: Number of layers in the decoder -
use_batch_norm_encoder: Whether to use batch normalization in the encoder - use_layer_norm_encoder: Whether to use layer normalization in the encoder - use_batch_norm_decoder: Whether to use batch normalization in the decoder - use_layer_norm_decoder: Whether to use layer normalization in the decoder - dropout_rate_encoder: Dropout rate in the encoder - dropout_rate_decoder: Dropout rate in the decoder - variational: Whether to use variational inference. NOTE: False
is highly recommended. - seed: Random seed
In this notebook, we left out B cells treated with IFN-beta from the training dataset (OOD set) and randomly split the remaining cells into train/valid sets. The split information is stored in adata.obs['split_B'] column. We would like to see if the model can predict how B cells can respond to IFN-beta stimulation.
[14]:
model = cpa.CPA(adata=adata,
split_key='split_B',
train_split='train',
valid_split='valid',
test_split='ood',
**model_params,
)
Global seed set to 6977
Training CPA#
In order to train your CPA model, you need to use train function of your model. This function accepts the following parameters: - max_epochs: Maximum number of epochs to train the model. CPA generally converges after high number of epochs, so you can set this to a high value. - use_gpu: If you have a GPU, you can set this to True to speed up the training process. - batch_size: Batch size for training. You can set this to a high value (e.g. 512, 1024, 2048) if you have a
GPU. - plan_kwargs: dictionary of parameters passed the CPA’s TrainingPlan. You can set the following parameters: * n_epochs_adv_warmup: Number of epochs to linearly increase the weight of adversarial loss. * n_epochs_mixup_warmup: Number of epochs to linearly increase the weight of mixup loss. * n_epochs_pretrain_ae: Number of epochs to pretrain the autoencoder. * lr: Learning rate for training autoencoder. * wd: Weight decay for training autoencoder. *
adv_lr: Learning rate for training adversary. * adv_wd: Weight decay for training adversary. * adv_steps: Number of steps to train adversary for each step of autoencoder. * reg_adv: Maximum Weight of adversarial loss. * pen_adv: Penalty weight of adversarial loss. * n_layers_adv: Number of layers in adversary. * n_hidden_adv: Number of hidden units in adversary. * use_batch_norm_adv: Whether to use batch normalization in adversary. *
use_layer_norm_adv: Whether to use layer normalization in adversary. * dropout_rate_adv: Dropout rate in adversary. * step_size_lr: Step size for learning rate scheduler. * do_clip_grad: Whether to clip gradients by norm. * clip_grad_value: Maximum value of gradient norm. * adv_loss: Type of adversarial loss. Can be either cce for Cross Entropy loss or focal for Focal loss. * n_epochs_verbose: Number of epochs to print latent information disentanglement
evaluation. - early_stopping_patience: Number of epochs to wait before stopping training if validation metric does not improve. - check_val_every_n_epoch: Number of epochs to wait before running validation. - save_path: Path to save the best model after training.
[15]:
model.train(max_epochs=2000,
use_gpu=True,
batch_size=512,
plan_kwargs=trainer_params,
early_stopping_patience=5,
check_val_every_n_epoch=5,
save_path='/home/mohsen/projects/cpa/lightning_logs/Kang/',
)
100%|██████████| 2/2 [00:00<00:00, 107.86it/s]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA RTX A6000') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Epoch 5/2000: 0%| | 4/2000 [00:09<1:04:14, 1.93s/it, v_num=1, recon=762, r2_mean=0.887, adv_loss=1.56, acc_pert=0.877, acc_cell_type=0.684]
Epoch 00004: cpa_metric reached. Module best state updated.
Epoch 10/2000: 0%| | 9/2000 [00:16<52:35, 1.58s/it, v_num=1, recon=738, r2_mean=0.914, adv_loss=1.04, acc_pert=0.93, acc_cell_type=0.731, val_recon=769, disnt_basal=1.22, disnt_after=1.54, val_r2_mean=0.847, val_KL=nan]
Epoch 00009: cpa_metric reached. Module best state updated.
disnt_basal = 1.1319586218021807
disnt_after = 1.5388108414048822
val_r2_mean = 0.8612706025441487
val_r2_var = 0.1454216930601332
Epoch 15/2000: 1%| | 14/2000 [00:25<55:32, 1.68s/it, v_num=1, recon=723, r2_mean=0.922, adv_loss=0.961, acc_pert=0.919, acc_cell_type=0.757, val_recon=758, disnt_basal=1.13, disnt_after=1.54, val_r2_mean=0.861, val_KL=nan]
Epoch 00014: cpa_metric reached. Module best state updated.
Epoch 20/2000: 1%| | 19/2000 [00:33<53:43, 1.63s/it, v_num=1, recon=712, r2_mean=0.925, adv_loss=0.915, acc_pert=0.904, acc_cell_type=0.772, val_recon=742, disnt_basal=1.05, disnt_after=1.54, val_r2_mean=0.878, val_KL=nan]
Epoch 00019: cpa_metric reached. Module best state updated.
disnt_basal = 1.0415280486446472
disnt_after = 1.5402086800792363
val_r2_mean = 0.891329390472836
val_r2_var = 0.3821916063626607
Epoch 25/2000: 1%| | 24/2000 [00:42<54:34, 1.66s/it, v_num=1, recon=703, r2_mean=0.928, adv_loss=0.887, acc_pert=0.904, acc_cell_type=0.775, val_recon=737, disnt_basal=1.04, disnt_after=1.54, val_r2_mean=0.891, val_KL=nan]
Epoch 00024: cpa_metric reached. Module best state updated.
Epoch 30/2000: 1%|▏ | 29/2000 [00:50<52:10, 1.59s/it, v_num=1, recon=695, r2_mean=0.929, adv_loss=0.858, acc_pert=0.904, acc_cell_type=0.783, val_recon=739, disnt_basal=1.02, disnt_after=1.54, val_r2_mean=0.899, val_KL=nan]
Epoch 00029: cpa_metric reached. Module best state updated.
disnt_basal = 1.0245505841664875
disnt_after = 1.5415955053897463
val_r2_mean = 0.8955810745557149
val_r2_var = 0.4310013135274251
Epoch 35/2000: 2%|▏ | 34/2000 [00:59<59:12, 1.81s/it, v_num=1, recon=690, r2_mean=0.931, adv_loss=1.01, acc_pert=0.856, acc_cell_type=0.763, val_recon=738, disnt_basal=1.02, disnt_after=1.54, val_r2_mean=0.896, val_KL=nan]
Epoch 00034: cpa_metric reached. Module best state updated.
Epoch 40/2000: 2%|▏ | 39/2000 [01:09<1:00:04, 1.84s/it, v_num=1, recon=685, r2_mean=0.931, adv_loss=2, acc_pert=0.605, acc_cell_type=0.581, val_recon=741, disnt_basal=0.881, disnt_after=1.54, val_r2_mean=0.896, val_KL=nan]
Epoch 00039: cpa_metric reached. Module best state updated.
disnt_basal = 0.7896260545340836
disnt_after = 1.540930079488082
val_r2_mean = 0.8923248264524671
val_r2_var = 0.42304009596506753
Epoch 45/2000: 2%|▏ | 44/2000 [01:17<57:12, 1.75s/it, v_num=1, recon=682, r2_mean=0.932, adv_loss=2.43, acc_pert=0.525, acc_cell_type=0.378, val_recon=740, disnt_basal=0.79, disnt_after=1.54, val_r2_mean=0.892, val_KL=nan]
Epoch 00044: cpa_metric reached. Module best state updated.
Epoch 50/2000: 2%|▏ | 49/2000 [01:27<57:43, 1.78s/it, v_num=1, recon=676, r2_mean=0.933, adv_loss=2.39, acc_pert=0.516, acc_cell_type=0.36, val_recon=742, disnt_basal=0.706, disnt_after=1.54, val_r2_mean=0.896, val_KL=nan]
Epoch 00049: cpa_metric reached. Module best state updated.
disnt_basal = 0.6914353259836439
disnt_after = 1.5408521704758549
val_r2_mean = 0.8931024220254686
val_r2_var = 0.45814667410320703
Epoch 55/2000: 3%|▎ | 54/2000 [01:36<1:00:03, 1.85s/it, v_num=1, recon=672, r2_mean=0.934, adv_loss=2.38, acc_pert=0.509, acc_cell_type=0.366, val_recon=745, disnt_basal=0.691, disnt_after=1.54, val_r2_mean=0.893, val_KL=nan]
Epoch 00054: cpa_metric reached. Module best state updated.
Epoch 60/2000: 3%|▎ | 59/2000 [01:46<59:25, 1.84s/it, v_num=1, recon=668, r2_mean=0.935, adv_loss=2.38, acc_pert=0.513, acc_cell_type=0.37, val_recon=746, disnt_basal=0.683, disnt_after=1.54, val_r2_mean=0.889, val_KL=nan]
Epoch 00059: cpa_metric reached. Module best state updated.
disnt_basal = 0.6731912757766404
disnt_after = 1.546922882959094
val_r2_mean = 0.8853998899459837
val_r2_var = 0.4678374422921075
Epoch 65/2000: 3%|▎ | 64/2000 [01:55<1:00:14, 1.87s/it, v_num=1, recon=664, r2_mean=0.935, adv_loss=2.37, acc_pert=0.51, acc_cell_type=0.366, val_recon=742, disnt_basal=0.673, disnt_after=1.55, val_r2_mean=0.885, val_KL=nan]
Epoch 00064: cpa_metric reached. Module best state updated.
Epoch 70/2000: 3%|▎ | 69/2000 [02:05<59:58, 1.86s/it, v_num=1, recon=660, r2_mean=0.936, adv_loss=2.38, acc_pert=0.505, acc_cell_type=0.357, val_recon=751, disnt_basal=0.668, disnt_after=1.54, val_r2_mean=0.896, val_KL=nan]
Epoch 00069: cpa_metric reached. Module best state updated.
disnt_basal = 0.6580392302196032
disnt_after = 1.5395934240909275
val_r2_mean = 0.8877692739168803
val_r2_var = 0.4790278262562222
Epoch 75/2000: 4%|▎ | 74/2000 [02:14<56:37, 1.76s/it, v_num=1, recon=657, r2_mean=0.936, adv_loss=2.38, acc_pert=0.502, acc_cell_type=0.359, val_recon=748, disnt_basal=0.658, disnt_after=1.54, val_r2_mean=0.888, val_KL=nan]
Epoch 00074: cpa_metric reached. Module best state updated.
Epoch 80/2000: 4%|▍ | 79/2000 [02:23<57:49, 1.81s/it, v_num=1, recon=654, r2_mean=0.935, adv_loss=2.37, acc_pert=0.503, acc_cell_type=0.355, val_recon=750, disnt_basal=0.66, disnt_after=1.54, val_r2_mean=0.894, val_KL=nan]
disnt_basal = 0.6571474352214841
disnt_after = 1.5428938608634823
val_r2_mean = 0.8882647699779934
val_r2_var = 0.4699256857236227
Epoch 85/2000: 4%|▍ | 84/2000 [02:32<59:01, 1.85s/it, v_num=1, recon=650, r2_mean=0.938, adv_loss=2.37, acc_pert=0.504, acc_cell_type=0.363, val_recon=756, disnt_basal=0.657, disnt_after=1.54, val_r2_mean=0.888, val_KL=nan]
Epoch 00084: cpa_metric reached. Module best state updated.
Epoch 90/2000: 4%|▍ | 89/2000 [02:42<59:08, 1.86s/it, v_num=1, recon=648, r2_mean=0.938, adv_loss=2.37, acc_pert=0.503, acc_cell_type=0.36, val_recon=750, disnt_basal=0.657, disnt_after=1.55, val_r2_mean=0.897, val_KL=nan]
disnt_basal = 0.6596201251185142
disnt_after = 1.538380862519362
val_r2_mean = 0.8955671522352432
val_r2_var = 0.49076554112964205
Epoch 95/2000: 5%|▍ | 94/2000 [02:50<55:14, 1.74s/it, v_num=1, recon=645, r2_mean=0.938, adv_loss=2.36, acc_pert=0.503, acc_cell_type=0.368, val_recon=759, disnt_basal=0.66, disnt_after=1.54, val_r2_mean=0.896, val_KL=nan]
Epoch 00094: cpa_metric reached. Module best state updated.
Epoch 100/2000: 5%|▍ | 99/2000 [03:00<56:58, 1.80s/it, v_num=1, recon=642, r2_mean=0.939, adv_loss=2.36, acc_pert=0.505, acc_cell_type=0.37, val_recon=759, disnt_basal=0.651, disnt_after=1.54, val_r2_mean=0.892, val_KL=nan]
disnt_basal = 0.6498720972741477
disnt_after = 1.5445982945793695
val_r2_mean = 0.8907546083132426
val_r2_var = 0.4707838972409566
Epoch 105/2000: 5%|▌ | 104/2000 [03:09<57:46, 1.83s/it, v_num=1, recon=639, r2_mean=0.939, adv_loss=2.36, acc_pert=0.502, acc_cell_type=0.364, val_recon=753, disnt_basal=0.65, disnt_after=1.54, val_r2_mean=0.891, val_KL=nan]
Epoch 00104: cpa_metric reached. Module best state updated.
Epoch 110/2000: 5%|▌ | 109/2000 [03:18<58:01, 1.84s/it, v_num=1, recon=636, r2_mean=0.94, adv_loss=2.36, acc_pert=0.506, acc_cell_type=0.374, val_recon=761, disnt_basal=0.651, disnt_after=1.54, val_r2_mean=0.9, val_KL=nan]
disnt_basal = 0.6581336091292386
disnt_after = 1.5487109645443529
val_r2_mean = 0.8913761708471509
val_r2_var = 0.49812944597668113
Epoch 115/2000: 6%|▌ | 114/2000 [03:28<57:13, 1.82s/it, v_num=1, recon=633, r2_mean=0.94, adv_loss=2.35, acc_pert=0.51, acc_cell_type=0.37, val_recon=759, disnt_basal=0.658, disnt_after=1.55, val_r2_mean=0.891, val_KL=nan]
Epoch 00114: cpa_metric reached. Module best state updated.
Epoch 120/2000: 6%|▌ | 119/2000 [03:37<55:56, 1.78s/it, v_num=1, recon=631, r2_mean=0.941, adv_loss=2.36, acc_pert=0.508, acc_cell_type=0.372, val_recon=760, disnt_basal=0.65, disnt_after=1.54, val_r2_mean=0.903, val_KL=nan]
Epoch 00119: cpa_metric reached. Module best state updated.
disnt_basal = 0.6475012395365286
disnt_after = 1.5389987631074236
val_r2_mean = 0.8979668233129713
val_r2_var = 0.5000029312239753
Epoch 130/2000: 6%|▋ | 129/2000 [03:55<56:46, 1.82s/it, v_num=1, recon=626, r2_mean=0.941, adv_loss=2.35, acc_pert=0.511, acc_cell_type=0.368, val_recon=763, disnt_basal=0.651, disnt_after=1.54, val_r2_mean=0.894, val_KL=nan]
Epoch 00129: cpa_metric reached. Module best state updated.
disnt_basal = 0.6484081169173904
disnt_after = 1.554791667815903
val_r2_mean = 0.8968017604615953
val_r2_var = 0.49864514536327786
Epoch 140/2000: 7%|▋ | 139/2000 [04:13<54:59, 1.77s/it, v_num=1, recon=622, r2_mean=0.942, adv_loss=2.35, acc_pert=0.517, acc_cell_type=0.379, val_recon=766, disnt_basal=0.649, disnt_after=1.54, val_r2_mean=0.889, val_KL=nan]
disnt_basal = 0.6389746154294813
disnt_after = 1.5448603553070959
val_r2_mean = 0.8946388085683187
val_r2_var = 0.5012603322664897
Epoch 150/2000: 7%|▋ | 149/2000 [04:32<56:53, 1.84s/it, v_num=1, recon=617, r2_mean=0.941, adv_loss=2.35, acc_pert=0.514, acc_cell_type=0.38, val_recon=768, disnt_basal=0.643, disnt_after=1.54, val_r2_mean=0.889, val_KL=nan]
disnt_basal = 0.6450572692000781
disnt_after = 1.5428375858029757
val_r2_mean = 0.892330677547152
val_r2_var = 0.52755427417301
Epoch 155/2000: 8%|▊ | 155/2000 [04:44<56:22, 1.83s/it, v_num=1, recon=615, r2_mean=0.942, adv_loss=2.34, acc_pert=0.52, acc_cell_type=0.38, val_recon=774, disnt_basal=0.643, disnt_after=1.54, val_r2_mean=0.902, val_KL=nan]
[16]:
cpa.pl.plot_history(model)

Restore best model#
In case you have already saved your pretrained model, you can restore it using the following code. The cpa.CPA.load function accepts the following arguments: - dir_path: path to the directory where the model is saved - adata: anndata object - use_gpu: whether to use GPU or not
[13]:
# model = cpa.CPA.load(dir_path='/home/mohsen/projects/cpa/lightning_logs/Kang/',
# adata=adata,
# use_gpu=True)
Latent Space Visualization#
latent vectors of all cells can be computed with get_latent_representation function. This function produces a python dictionary with the following keys: - latent_basal: latent vectors of all cells in basal state of autoencoder - latent_after: final latent vectors which can be used for decoding - latent_corrected: batch-corrected latents if batch_key was provided
[22]:
latent_outputs = model.get_latent_representation(adata, batch_size=2048)
100%|██████████| 7/7 [00:01<00:00, 6.73it/s]
[23]:
latent_outputs.keys()
[23]:
dict_keys(['latent_corrected', 'latent_basal', 'latent_after'])
[24]:
sc.pp.neighbors(latent_outputs['latent_basal'])
sc.tl.umap(latent_outputs['latent_basal'])
WARNING: You’re trying to run this on 64 dimensions of `.X`, if you really want this, set `use_rep='X'`.
Falling back to preprocessing with `sc.pp.pca` and default params.
As observed below, the basal representation should be free of the variation(s) of the condition and cell_type.
[27]:
sc.pl.umap(latent_outputs['latent_basal'],
color=['condition', 'cell_type'],
frameon=False,
wspace=0.3)
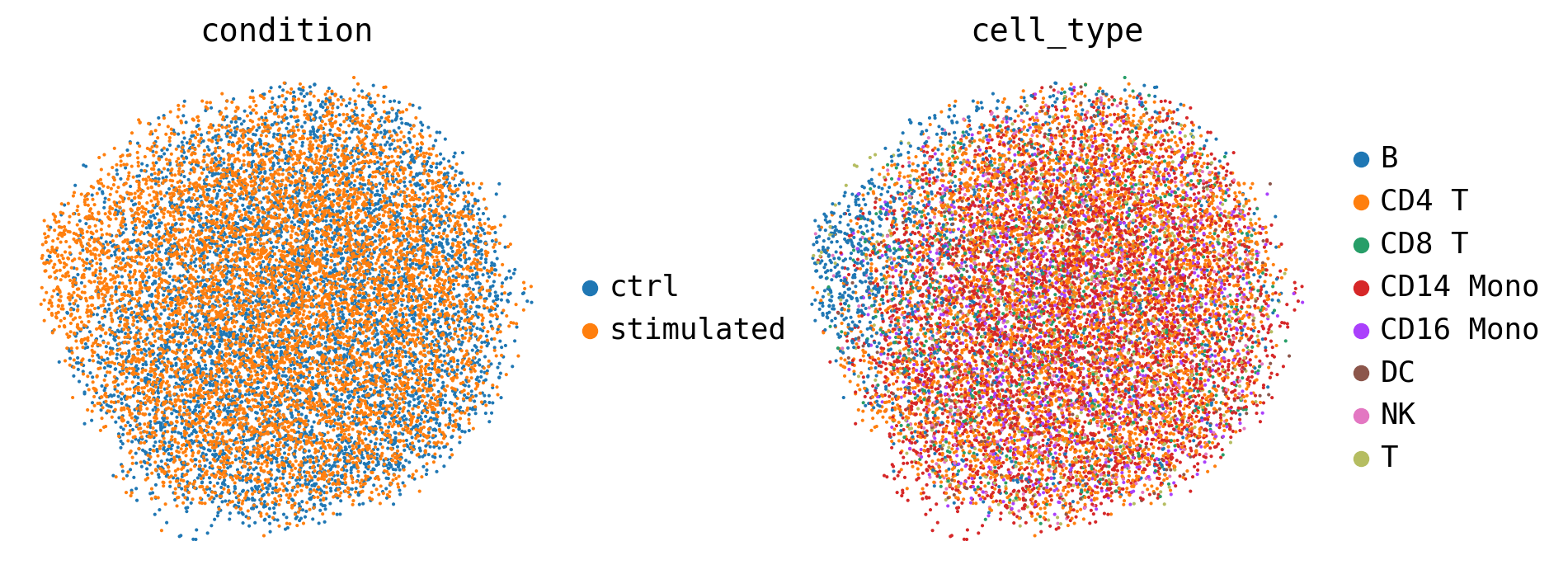
[28]:
sc.pp.neighbors(latent_outputs['latent_after'])
sc.tl.umap(latent_outputs['latent_after'])
WARNING: You’re trying to run this on 64 dimensions of `.X`, if you really want this, set `use_rep='X'`.
Falling back to preprocessing with `sc.pp.pca` and default params.
Here, you can visualize that when the condition and cell_type embeddings are added to the basal representation, As you can see now cell types and conditions are separated.
[29]:
sc.pl.umap(latent_outputs['latent_after'],
color=['condition', 'cell_type'],
frameon=False,
wspace=0.3)

Evaluation#
To evaluate the model’s prediction performance, we can use model.predict() function. \(R^2\) score for each combination of <cell_type, stimulated> is computed over mean statistics of the top 50, 20, and 10 DEGs (including all genes). CPA transfers the context from control to IFN-beta stimulated for each cell type. Next, we will evaluate the model’s prediction performance on the whole dataset, including OOD (test) cells. The model will report metrics on how well we have captured the
variation in top n differentially expressed genes when compared to control cells (CTRL) for each condition. The metrics calculate the mean accuracy (r2_mean_deg), the variance (r2_var_deg) and similar metrics (r2_mean_lfc_deg and log fold change)to measure the log fold change of the predicted cells vs control((LFC(control, ground truth) ~ LFC(control, predicted cells)). The R2 is the sklearn.metrics.r2_score from
sklearn.
[ ]:
model.predict(adata, batch_size=2048)
100%|██████████| 7/7 [00:01<00:00, 5.87it/s]
[ ]:
import numpy as np
import pandas as pd
from sklearn.metrics import r2_score
from collections import defaultdict
from tqdm import tqdm
n_top_degs = [10, 20, 50, None] # None means all genes
results = defaultdict(list)
for cat in tqdm(adata.obs['cov_cond'].unique()):
if 'ctrl' not in cat:
cov, condition = cat.split('_')
cat_adata = adata[adata.obs['cov_cond'] == cat].copy()
ctrl_adata = adata[adata.obs['cov_cond'] == f'{cov}_ctrl'].copy()
deg_cat = f'{cat}'
deg_list = adata.uns['rank_genes_groups_cov'][deg_cat]
x_true = cat_adata.layers['counts']
x_pred = cat_adata.obsm['CPA_pred']
x_ctrl = ctrl_adata.layers['counts']
x_true = np.log1p(x_true)
x_pred = np.log1p(x_pred)
x_ctrl = np.log1p(x_ctrl)
for n_top_deg in n_top_degs:
if n_top_deg is not None:
degs = np.where(np.isin(adata.var_names, deg_list[:n_top_deg]))[0]
else:
degs = np.arange(adata.n_vars)
n_top_deg = 'all'
x_true_deg = x_true[:, degs]
x_pred_deg = x_pred[:, degs]
x_ctrl_deg = x_ctrl[:, degs]
r2_mean_deg = r2_score(x_true_deg.mean(0), x_pred_deg.mean(0))
r2_var_deg = r2_score(x_true_deg.var(0), x_pred_deg.var(0))
r2_mean_lfc_deg = r2_score(x_true_deg.mean(0) - x_ctrl_deg.mean(0), x_pred_deg.mean(0) - x_ctrl_deg.mean(0))
r2_var_lfc_deg = r2_score(x_true_deg.var(0) - x_ctrl_deg.var(0), x_pred_deg.var(0) - x_ctrl_deg.var(0))
results['condition'].append(condition)
results['cell_type'].append(cov)
results['n_top_deg'].append(n_top_deg)
results['r2_mean_deg'].append(r2_mean_deg)
results['r2_var_deg'].append(r2_var_deg)
results['r2_mean_lfc_deg'].append(r2_mean_lfc_deg)
results['r2_var_lfc_deg'].append(r2_var_lfc_deg)
df = pd.DataFrame(results)
100%|██████████| 16/16 [00:02<00:00, 7.44it/s]
[ ]:
df
| condition | cell_type | n_top_deg | r2_mean_deg | r2_var_deg | r2_mean_lfc_deg | r2_var_lfc_deg | |
|---|---|---|---|---|---|---|---|
| 0 | stimulated | CD8 T | 10 | 0.914757 | -6.352824 | 0.874114 | -4.331145 |
| 1 | stimulated | CD8 T | 20 | 0.922747 | -4.049037 | 0.890461 | -3.286699 |
| 2 | stimulated | CD8 T | 50 | 0.934652 | -0.248928 | 0.908343 | -2.016761 |
| 3 | stimulated | CD8 T | all | 0.962284 | 0.615588 | 0.878685 | -0.958518 |
| 4 | stimulated | CD4 T | 10 | 0.929220 | -47.121994 | 0.902127 | -2.336050 |
| 5 | stimulated | CD4 T | 20 | 0.943253 | -7.026309 | 0.920049 | -2.403320 |
| 6 | stimulated | CD4 T | 50 | 0.951094 | -0.103031 | 0.935860 | -1.589643 |
| 7 | stimulated | CD4 T | all | 0.964227 | 0.534098 | 0.896550 | -1.210343 |
| 8 | stimulated | B | 10 | 0.706361 | -0.479692 | 0.521262 | -0.119935 |
| 9 | stimulated | B | 20 | 0.784455 | -0.824876 | 0.713866 | -0.421662 |
| 10 | stimulated | B | 50 | 0.770382 | -1.206571 | 0.758324 | -0.632753 |
| 11 | stimulated | B | all | 0.832034 | 0.449393 | 0.534297 | -0.621387 |
| 12 | stimulated | CD14 Mono | 10 | 0.992861 | 0.722882 | 0.991362 | 0.810340 |
| 13 | stimulated | CD14 Mono | 20 | 0.984898 | 0.720628 | 0.984483 | 0.792081 |
| 14 | stimulated | CD14 Mono | 50 | 0.991053 | 0.381264 | 0.992555 | 0.601384 |
| 15 | stimulated | CD14 Mono | all | 0.991880 | 0.793317 | 0.981210 | 0.637431 |
| 16 | stimulated | T | 10 | 0.830578 | -2.304788 | 0.684173 | -13.269615 |
| 17 | stimulated | T | 20 | 0.872823 | -0.995450 | 0.812437 | -1.345000 |
| 18 | stimulated | T | 50 | 0.912229 | -0.029362 | 0.886567 | -0.257559 |
| 19 | stimulated | T | all | 0.954346 | 0.654386 | 0.841398 | -0.506765 |
| 20 | stimulated | NK | 10 | 0.940082 | -5.274147 | 0.918704 | -1.475819 |
| 21 | stimulated | NK | 20 | 0.933483 | -4.634543 | 0.915638 | -3.232631 |
| 22 | stimulated | NK | 50 | 0.933923 | -1.380222 | 0.935201 | -1.939416 |
| 23 | stimulated | NK | all | 0.969149 | 0.553978 | 0.906959 | -1.132814 |
| 24 | stimulated | DC | 10 | 0.993851 | 0.301764 | 0.991290 | 0.753526 |
| 25 | stimulated | DC | 20 | 0.983294 | 0.535610 | 0.981660 | 0.679639 |
| 26 | stimulated | DC | 50 | 0.984448 | 0.175052 | 0.987295 | 0.568996 |
| 27 | stimulated | DC | all | 0.990917 | 0.728622 | 0.974018 | 0.452947 |
| 28 | stimulated | CD16 Mono | 10 | 0.987389 | 0.188611 | 0.983049 | 0.799025 |
| 29 | stimulated | CD16 Mono | 20 | 0.993985 | 0.562261 | 0.992568 | 0.653976 |
| 30 | stimulated | CD16 Mono | 50 | 0.990753 | -0.147736 | 0.989940 | 0.271904 |
| 31 | stimulated | CD16 Mono | all | 0.991023 | 0.739061 | 0.972573 | 0.268257 |